Tags
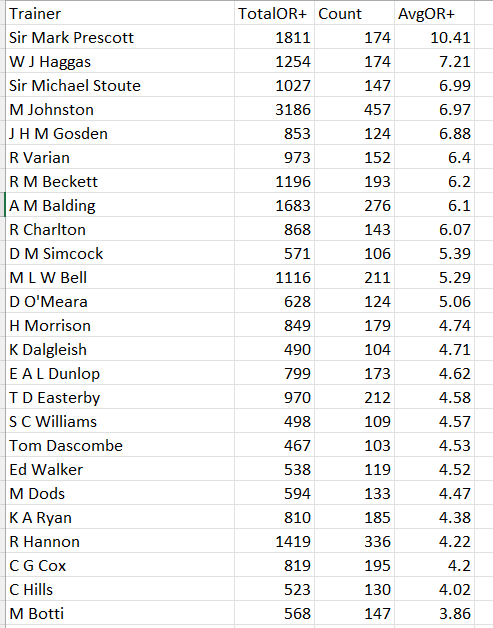
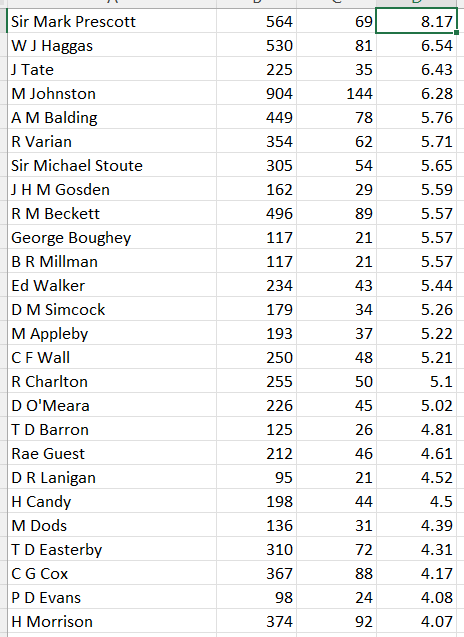
What should we be looking at with regard to trainers in lets say a class 5 or 6 handicap horse race. Current trainer form ?, jockey booking ?, course record ?. Different pundits have different preferences but usually current form figures strongly. One possible problem with this is that we are lumping all trainers together. Trainers most likely have a different pecking order of influences that effect their winning ability. Using MySportsAI you can check the correlation of an array of factors for a given trainer but on this occassion I decided to write some Python code to go through all the features in MySportsAI and order them in terms of correlation to winning for each trainer with more than 500 runs from 2011 to 2019.
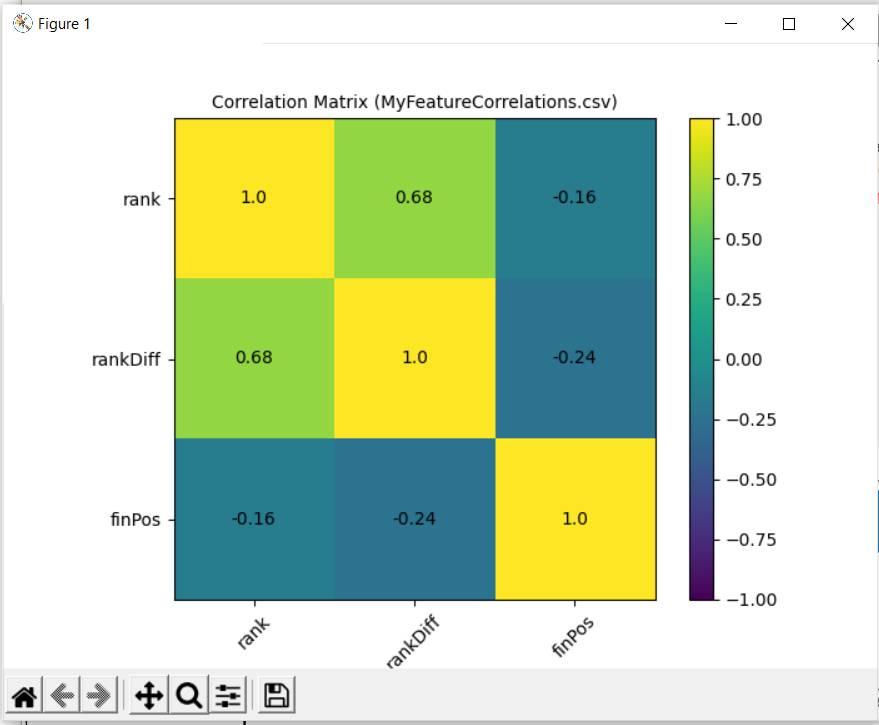
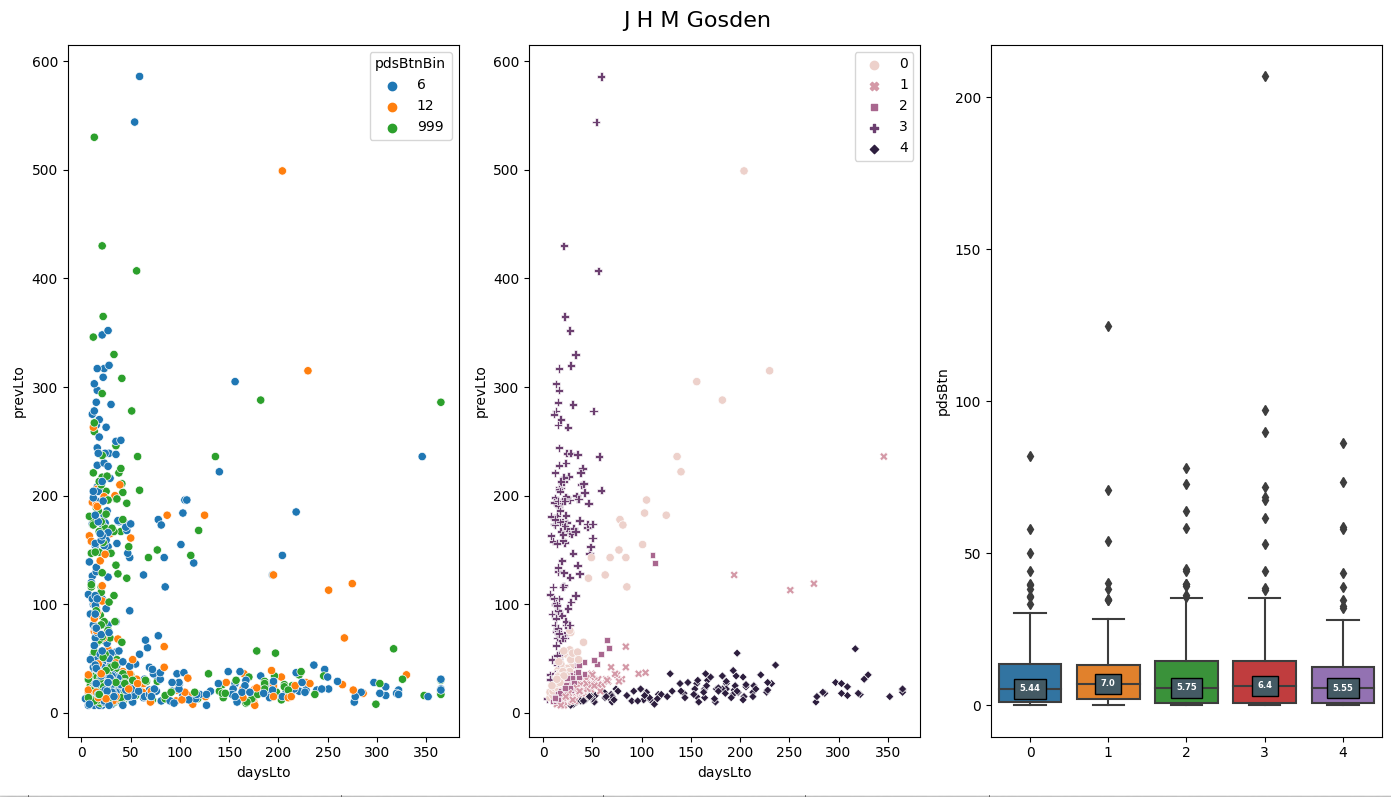
Let’s look at a specific example before getting carried away with models. The vast majority of trainers have a negative correlation between days since last run and winning. This correlation varies in size but a few have a positive correlation. M Johnston (now retired is one). It is not his strongest feature but he does buck the trend.
I identified that the top 4 correlated features for R A Fahey, they are runnerRatio hasPlacedTrack beatLto1 logPrevBFSP
Things are not the same for Karl Burke, he has the same top ranked feature but in second is the average track win pace (I would have to dig further to find out why) and in third is whether the horse has placed at the track
The idea I am leading to is whether individual models based on the relevant features for each trainer could lead to a more precise ability to detect when a trainer is most likely to win. Of course if the market accounts for this we may be up a cul de sac but we will not know until test the idea.
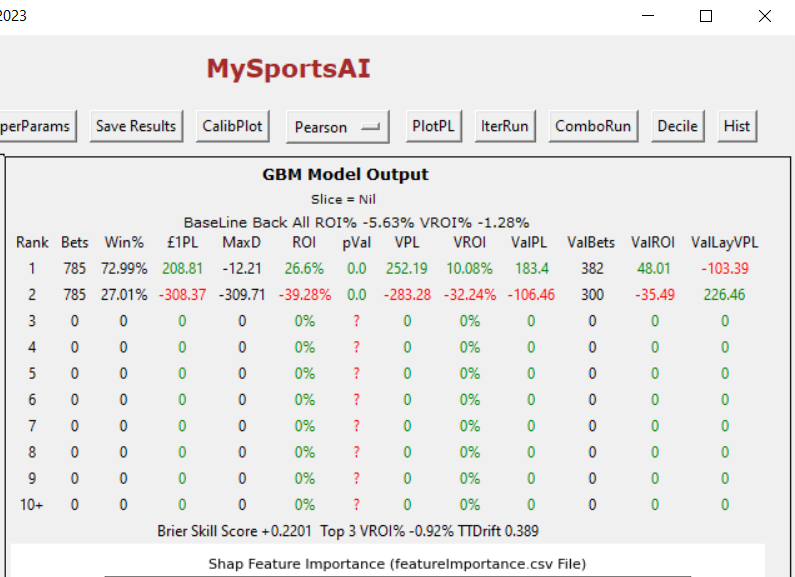
My first port of call was to create models for each trainer based on the top (in terms of correlation to winning) X features for each trainer. The next step was to see if the predicted probabilities for races the trainer had runners in within the test set (in this case 2021 to 2023) performed better when they were greater than the trainers base win rate. I focused the attention down to handicaps of class 5,6 and 7. I think class has an impact on how horses are prepared and hence the correlation of features. I started with K Nearest Neighbor algorithm for the model taking care to normalise all features that were used in the models. Here are the results for various number of top ranked features, that is to say using only the top feature for each trainer and then the top 2, top 3 etc. All profit/loss is to Betfair SP minus 2% commission
Using top 1 feature and probability greater than trainer base strike rate
Bets 10,126 Variable PL +7.64 Variable ROI% 0.43%
Using 1 feature and probability less than base strike rate
Bets 25,272 VPL -103.66 VROI% -3.15%
Using top 2 features and probability greater than base strike rate
Bets 8,856 VPL -12.92 VROI% -0.87%
Using top 2 features and probability less than base strike rate
Bets 25,028 VPL -105.68 VROI% -3.14%
Using top 3 features and probability greater than base strike rate
Bets 10,661 VPL -58.2 VROI% -3.05%
Using top 3 features and probability less than base strike rate
21,913 VPL -68.3 VROI% -2.47%
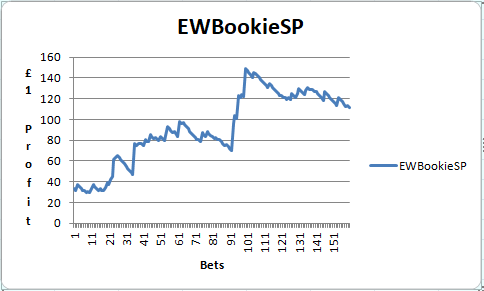
Four features continued the trend and so it seems that less is more in this case. The generation of a small profit is encouraging. A next step may be to investigate different model algorithms. A quick look at a GBM produced.
Using top 1 feature and probability greater than trainer base strike rate
Bets 11,431 Variable PL -26.8 Variable ROI% -1.43%
A Logistic Regression model produced
Using top 1 feature and probability greater than trainer base strike rate
Bets 10,762 Variable PL +16.96 Variable ROI% +0.89%